научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
#10 октябрь 2007
А.Д.Козлов, С.Ю.Шуйков
Современные информационные системы характеризуются сложной структурой и внутренней логикой. К настоящему времени разработано множество методик и подходов для качественного и оптимального проектирования информационных систем, позволяющих обеспечить модульность разработки, разделить её на параллельные процессы и минимизировать количество ошибок. Наиболее широкое распространение получила парадигма объектно-ориентированного программирования. Объектно-ориентированная парадигма или объектно-ориентированная модель, заложенная классиками этого подхода [1], хорошо описана и в применении к конкретным языкам программирования [4,7].
Одним из важных свойств объектов, используемых при построении информационных систем является его Сохраняемость (Persistence) – способность объекта существовать во времени независимо от породившего его процесса. Следует отметить, что сохраняемость в общем случае сводится не только к сохранению данных объекта, но может также потребовать сохранения иерархии классов для последующей корректной обработки объекта. Естественно, реализация данного свойства требует использования систем управления базами данных.
В области хранения и манипулирования данными наибольшие успехи достигнуты при помощи реляционного подхода, реализующего модель сущностей-связей. Современные реляционные СУБД, имея в основе строгий математический аппарат [5,6] и развитые алгоритмы обработки больших объёмов данных, заняли лидирующие положение в качестве конечного (терминального) хранилища данных.
Попытки создания индустриальных стандартов для объектных или объектно-ориентированных систем управления базами данных (ОСУБД или ООСУБД) [8,9,10] привели к появлению множества реализаций ООСУБД как экспериментального, так и промышленного характера [11]. Однако отсутствие единых стандартов для таких СУБД, недостаточная масштабируемость, сложность и значительные накладные расходы по использованию ресурсов не позволяют им получить широкое распространение, конкурировать или даже пытаться вытеснить реляционные СУБД. В результате, при проектировании значительного числа информационных систем практические разработчики предпочитают использовать объектно-ориентированную парадигму при создании программной модели информационной системы в паре с реляционной СУБД как постоянного хранилища (persistence storage) для объектной модели.
Взаимодействие с реляционными СУБД ведется с использованием языка SQL [2] в рамках формальных реляционных терминов: отношение (таблица), кортеж (строка таблицы или запись), атрибут (столбец или поле), первичный ключ, домен и т.д. При этом естественным образом возникает проблема отображения свойств объектной модели в реляционную базу данных. Решением этой задачи является создание посредника - объектно-реляционного проектора (ОРП) (Object Relational Mapper - ORM) между объектно-ориентированной средой и реляционными базами данных для обеспечения отображения состояния объектов в реляционные хранилища, их целостности и идентичности. Методики и шаблоны (patterns), используемые при разработке ORM, хорошо описаны [12]; кроме того, существует большое количество готовых реализаций [13, 17].
При разработке ORM следует уделить особое внимание его оптимизации, особенно методов загрузки (инициализации) состояния объектов из реляционной базы, сохранения состояния и выполнения методов объектов. Отсутствие должного внимания к этим вопросам может серьёзно ухудшить производительность системы при росте количества запросов (например, для публичных web-приложений).
При разработке объектной модели одной из важных задач является построение иерархий – упорядочение абстракций, расположение их по уровням, построение направленного графа абстракций. Можно выделить два основных вида иерархических структур классов при построении сложных информационных систем: иерархия «is-a» и иерархия «part-of». Можно привести следующие примеры иерархий:
· Наследование - отношение между классами (отношение потомок-родитель, иерархия вида «is-a»), когда один класс воспроизводит структуру и/или функционал одного или нескольких других классов (одиночное или множественное наследование). При этом потомок может добавлять новые и/или изменять существующие компоненты класса(ов) родителя(ей).
· Агрегация – объединение логически связанных структур и установление отношения владения или принадлежности (иерархия вида «part-of»).
Построенные иерархии объектной модели находят своё отражение в реляционной структуре базы данных. Существует три основных стратегии отображения иерархии наследования [14]:
1. Единая таблица, агрегирующая базовый класс и его потомков.
2. Группировка общих свойств класса и его потомков в одной таблице и выделение уникальных свойств потомков в отдельные таблицы.
3. Создание отдельной таблицы для каждого класса объектов.
Иерархия агрегации также может быть отображена различными способами: как включением агрегируемого объекта в таблицу основного объекта – встраивание объекта (embedded object [12]), так и вынесением агрегируемого объекта в отдельную таблицу с созданием внешнего ключа у основного объекта.
Рассмотрим пример объектной модели имеющей иерархии обоих типов. На рис. 1 изображена общая диаграмма классов.
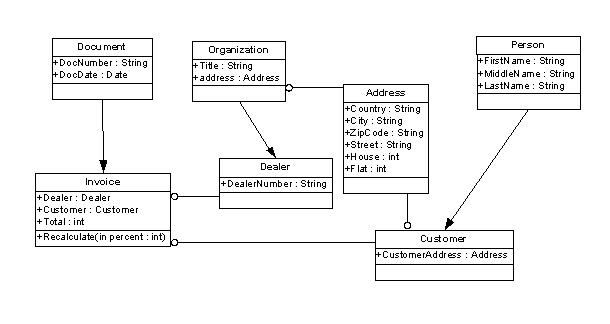
Рис. 1. Общая диаграмма классов
Выделим отдельно иерархии наследования - «is-a» (рис. 2 ) и агрегации «part-of» (рис. 3).

Рис. 2 Пример иерархии наследования - «is-a»
Связи вида «is-a» и «part-of» образуют направленные независимые графы, причём некоторые из объектов могут не входить ни в одну из иерархий.
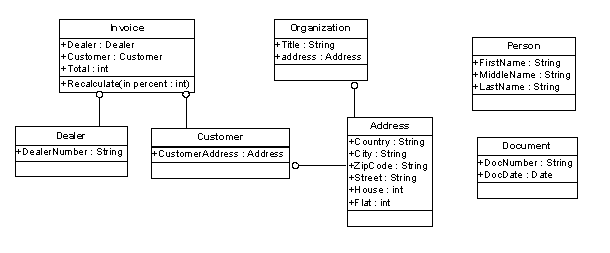
Рис. 3 Пример иерархии агрегации - «part-of»
Ни одна из стратегий не является оптимальной для произвольной структуры классов, поэтому разработчик, выбирая ту или иную стратегию, руководствуется набором рекомендаций и своим опытом [14]. Отметим что различные стратегии отображения можно совмещать в рамках одной базы данных для разных классов.
В нашем примере используем стратегию 2, при отображении объектной модели в реляционную структуру создадим отдельные таблицы для уникальных наборов свойств из классов, считая что все они не являются абстрактными, т.е допускают создание экземпляра класса: Document – Invoice, Organization – Dealer, Person – Customer; используем также отдельную таблицу для агрегируемого объекта Address. Полученная структура базы данных представлена на рис. 4.
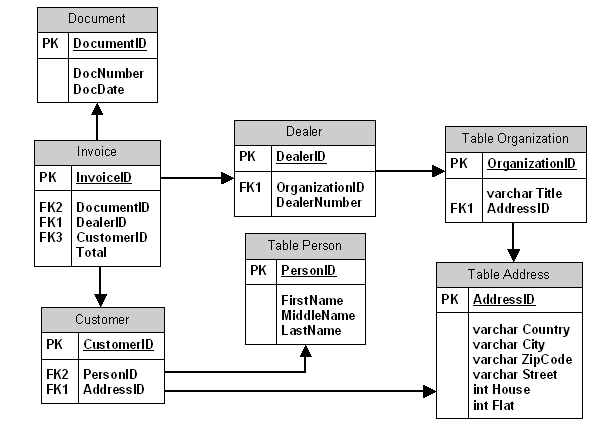
Рис. 4 Структура реляционной базы данных
В схеме реляционной базы данных иерархии обоих видов («is-a» и «part-of») представлены в виде связей между таблицами с использованием внешних ключей (foreign keys). В отличие от объектной модели эти связи двунаправлены, т.е. по внешнему ключу можно получить список объектов которые на него ссылаются, тогда как иерархия вида «part-of» не позволяет этого сделать в объектной модели.
С точки зрения предметной области, моделируемой представленной структурой, основным объектом является Invoice, который используется как отправная точка в сценариях работы пользователя. Следовательно, в общем случае при работе с экземпляром объекта Invoice требуется наличие всех связанных с ним объектов (графа объектов). Последовательность создания такого графа посредством загрузки связанных объектов будет выглядеть как набор SQL-команд выборки данных:
SELECT * FROM Invoice WHERE InvoiceID=@InvoiceID
SELECT * FROM Document WHERE Document ID=@DocumentID
SELECT * FROM Dealer WHERE DealerID=@DealerD
SELECT * FROM Organization WHERE Organization ID=@OrganizationID
SELECT * FROM Address WHERE AddressID=@OrganizationAddressID
SELECT * FROM Customer WHERE CustomerID=@CustomerD
SELECT * FROM Person WHERE PersonID=@PersonID
SELECT * FROM Address WHERE AddressID=@PersonAddressID
Однако в некоторых сценариях работы часть объектов может просто не потребоваться: к примеру, представление документа Invoice без адресов не требует наличия объекта Address в графе загруженных объектов. Таким образом, в некоторых случаях можно избежать загрузки этих объектов, сократив число обращений к базе данных.
Другим примером неоптимальной реализации свойств объектной модели является массовое обновление объектов одного типа. Допустим, у объекта Invoice есть метод Recalculate(percent), в результате выполнения которого свойство Total увеличивается на указанную в параметре процентную долю. При вызове этого метода с единым значением параметра (допустим, 10%) для всех объектов Invoice из некоторой коллекции InvoiceCollection (заданной, к примеру, в некотором диапазоне дат) последовательность SQL-команд обновления будет выглядеть:
UPDATE Invoice SET Total=Total*1.1 WHERE InvoiceID=@InvoiceID1
UPDATE Invoice SET Total=Total*1.1 WHERE InvoiceID=@InvoiceID2
…
UPDATE Invoice SET Total=Total*1.1 WHERE InvoiceID=@InvoiceIDn
где InvoiceID1,InvoiceID2…InvoiceIDn - множество идентификаторов объектов Invoice из коллекции InvoiceCollection.
Очевидно, что данная последовательность SQL-команд может быть заменена одной командой вида:
UPDATE Invoice SET Total=Total*1.1 WHERE InvoiceID IN (InvoiceID1,
InvoiceID2, … , InvoiceIDn)
Рассмотрим, каким образом такая оптимизация может быть выполнена автоматически с использованием ORM.
Как было сказано выше, построение графа загружаемых связанных объектов осуществляется последовательностью SQL-команд выборки данных. Вообще говоря, нет необходимости их группового выполнения, т.е. моменты выполнения команд могут быть отложены до тех пор, пока нет обращения к объекту, который они инициализируют (отложенная загрузка – «postponed load»). Более того, некоторые команды могут и не выполняться вообще, если в сценарии отсутствует обращение к какому-то из объектов. Данный метод известен как «загрузка по требованию» («load-on-demand»). Достоинством этого метода является возможное уменьшение обращений к базе данных. Недостатком же является затруднение в объединении нескольких SQL-команд выборки вида:
SELECT * FROM Invoice WHERE InvoiceID=@InvoiceID
SELECT * FROM Document WHERE Document ID=@DocumentID
в одну:
SELECT * FROM Invoice INNER JOIN Dealer Invoice.DealerID = Dealer.DealerID WHERE InvoiceID=@InvoiceID
Подобное объединение является эффективным т.к. известно, что сервера СУБД несут дополнительные накладные расходы на каждый SQL-запрос (синтаксический анализ и разбор, построение плана выполнения (execution plan) и т.д.).
Метод загрузки требованию («load-on-demand») позволяет сократить число SQL- команд, однако продолжает фиксировать время начала их выполнения (команда на загрузку связанного объекта начнет выполняться не раньше обращения к нему через объектную модель), что сокращает дальнейшие возможности оптимизации.
Загрузка связанного объекта может начаться в промежутке между загрузкой основного объекта и обращения к связанному объекту в отдельном процессе (асинхронно) с меньшим приоритетом. Для гарантированного наличия связанного объекта в памяти мы должны дождаться окончание его загрузки перед обращением к нему, т.е. данный метод «ленивой загрузки» («lazy load») можно рассматривать как альтернативу «загрузки по требованию» («load-on-demand»). Несмотря на то, что число обращений к базе данных в этом случае не уменьшается, подсистема очереди выполнения запросов способна эффективно оптимизировать их выполнение. Во-первых, за счет того, что мы способны явно задать приоритеты выполнения запросов. Во-вторых, время начала их выполнения не зафиксировано жёстко, следовательно, можно отсортировать очередь запросов, сгруппировав однотипные запросы (запросы к одним и тем же таблицам). Например, следующая очередь запросов:
SELECT * FROM Organization WHERE Organization ID=@OrganizationID
SELECT * FROM Address WHERE AddressID=@OrganizationAddressID -- low priority
SELECT * FROM Customer WHERE CustomerID=@CustomerD
SELECT * FROM Address WHERE AddressID=@PersonAddressID -- low priority
может быть перегруппирована в:
SELECT * FROM Organization WHERE Organization ID=@OrganizationID
SELECT * FROM Customer WHERE CustomerID=@CustomerD
SELECT * FROM Address WHERE AddressID=@OrganizationAddressID -- low priority
SELECT * FROM Address WHERE AddressID=@PersonAddressID -- low priority
и даже объединена в:
SELECT * FROM Organization WHERE Organization ID=@OrganizationID
SELECT * FROM Customer WHERE CustomerID=@CustomerD
SELECT * FROM Address WHERE AddressID IN (OrganizationAddressID, PersonAddressID) -- low priority
Эффективность данного метода достигается за счет выполнения последовательных запросов к одной и той же таблице (таблицам). Это связанно с особенностями страничного кэширования данных и кэширования планов выполнения в SQL-серверах [15].
Методы оптимизации на основе «ленивой загрузки» («lazy load») и объединения запросов известны и широко используются в существующих ОРП [18, 19]. Однако переключение между различными стратегиями выборки данных (fetching strategies) осуществляется на этапе проектирования, их изменение на этапе выполнения ограничено; кроме того, не указаны критерии выбора той или иной стратегии.
Современные СУБД способны эффективно выполнять сложные SQL-запросы за счет высокой оптимизации планов выполнения. Важную роль в такой оптимизации играет статистика, которую накапливает сервер базы данных. Благодаря статистике подсистема построения планов выполнения способна кардинально изменить план или даже выбрать альтернативный вариант, что приводит к существенному улучшению производительности в целом.
В рамках оптимизации методов загрузки объектов из базы данных также можно накапливать и использовать статистику, но уже не в разрезе реляционных данных, а в разрезе объектной модели. Это позволит принимать решение об использовании того или иного метода оптимизации на этапе выполнения программы. Так, можно создать класс вида:
class ObjectStatistic
{
Type LoadingType;
Type[] ReferencedTypes;
Type[] LoadedTypes;
int[] ReferenceRequested;
int[] ReferenceOmitted;
}
где LoadingType – загружаемый в данный момент тип объекта,
ReferencedTypes – массив типов объектов, на которые ссылается загружаемый объект в соответствии с иерархиями наследования «is-a» и агрегации «part-of»,
LoadedTypes – массив уже загруженных типов объектов,
ReferenceRequested – количество случаев когда были обращения (и потребовалась их загрузка) связанного объекта соответствующего типа из ReferencedTypes,
ReferenceOmitted – количество случаев, когда таких обращений не было.
Коллекция объектов типа ObjectStatistic для всех типов LoadingType составляет статистику для всей объектной модели. В процессе загрузки экземпляра определенного объекта для него извлекается статистика по данному типу и для каждого из связанных объектов (из ReferencedTypes) может быть принято решение о методе его загрузки в соответствии со значениями ReferenceRequested и ReferenceOmitted.
Так при значительном превышении ReferenceRequested над ReferenceOmitted (означающим, что связанный объект будет затребован с большой вероятностью) может быть выбран метод немедленной загрузки связанного объекта единым запросом с основным объектом вида:
SELECT * FROM Invoice INNER JOIN Dealer Invoice.DealerID = Dealer.DealerID WHERE InvoiceID=@InvoiceID
При примерном равенстве значений ReferenceRequested и ReferenceOmitted загрузка связанного объекта может быть выполнена асинхронно в отдельном потоке с пониженным приоритетом (метод «lazy load»)
SELECT * FROM Invoice WHERE InvoiceID=@InvoiceID
SELECT * FROM Dealer WHERE DealerID=@DealerD – low priority
Наконец при значительном превышении ReferenceOmitted над ReferenceRequested используется метод «загрузки по требованию» («load-on-demand»), т.к. высока вероятность того, что связанный объект может не понадобиться, и удастся избежать лишнего обращения к базе данных.
Кроме данных о типах объектов возможно введение и других параметров в статистику. Так, для большого числа приложений характерно наличие определённого набора сценариев пользователя (например, создание документа Invoice, проведение документа Invoice, печать документа и т.д.), что выражается в однотипной последовательности действий (а значит, и взаимодействия с базой данных) объектной модели. Такой параметр как «сценарий» можно ввести в статистику и передавать приложением в ORM.
Обновление значений ReferenceRequested должно происходить при обращении к соответствующему объекту, а ReferenceOmitted – перед разрушением основного объекта в памяти путем определения тех связанных объектов, которые так и не были загружены.
Все статистические данные должны располагаться в оперативной памяти, чтобы избежать дополнительных запросов к базе данных, которые могут свести на нет весь эффект от их использования. В этом случае в начале работы программы происходит накопление статистики, которая затем используется до закрытия программы. Однако возможно и сохранение этих данных между сеансами работы приложения. При запуске приложения накопленная статистика однократно загружается в оперативную память, затем в процессе работы программы идет её обновление, а перед завершением сеанса происходит её сохранение в базу данных. Реляционная структура для объектов статистики может быть сформирована с помощью ORM так же как для других элементов объектной модели.
Одним из важнейших критериев реализации ORM является его «прозрачность» с точки зрения самой объектной модели, т.е. независимость кода, работающего с объектной моделью и инкапсулированного кода самой объектной модели. К сожалению, не все реализации методов оптимизации удовлетворяют этому требованию. Так, простейшая реализация методов «загрузки по требованию» («load-on-demand») и «ленивой загрузки» («lazy load») состоит в использовании возможности в современных языках (C#) обращаться к методам через члены объекта. Например, определение свойства объекта в C#:
class FooObject
{
public PropertyType PropertyName
get {…}
set {…}
}
фактически означает определение двух методов PropertyType get_PropertyName() и void set_PropertyName(PropertyType), позволяя в методе get_ заложить необходимую логику в виде:
get
{
if(!propertyData.IsLoaded)
propertyData.LoadImmediately(); // load on demand
// propertyData.WaitForPendingLoad(); // lazy load
return propertyData;
}
Такая реализация обеспечит «прозрачность» для кода внешнего по отношению к объекту FooObject, но потребует изменения кода самого объекта FooObject если он был разработан без учёта этих особенностей. Создание оптимизированного ORM, не требующего модификации оригинальной объектной модели, возможно при использовании метаданных кода, т.е. возможности получения данных о членах и методах класса объектов на этапе компиляции и выполнения [16]. Возможно также расширение объектной модели с использованием специальных классов оберток (wrappers) и доступа (proxy), способных обеспечить «прозрачность» ОРП [18]. Другие варианты оптимизации могут потребовать введения дополнительной функциональности не только в объектную модель. К примеру, использование параметра «сценарий» в статистике потребует отслеживать его на уровне интерфейса пользователя (user UI) и обеспечивать сквозную передачу через объектную модель в ORM.
Заметим, что под «связанным объектом» могут подразумеваться не только объекты из иерархии агрегирования, но и объекты родитель-наследники. В этом случае использование методов отложенных загрузок («postponed load») при некоторых вариантах реализации ORM (стратегия 2) может приводить к появлению в памяти частично загруженных объектов, для которых инициализированы только уникальные атрибуты, а общие атрибуты (атрибуты класса предка) - еще нет, так как загрузка самого экземпляра класса предка еще не произведена. Для решения этой проблемы ORM должен обрабатывать обращения к членам класса-предка способом, аналогичным обращению к агрегируемому объекту.
Методы оптимизации загрузки из базы данных могут быть применены не только при загрузке отдельного объекта (графа связанных объектов), но и при работе с коллекциями объектов одного типа. Обычными методами класса коллекции являются:
Add(Object) – добавление объекта в коллекцию. Метод может быть выполнен без загрузки других элементов коллекции из базы данных;
bool Contains(Object) - поиск элемента в коллекции. Требует загрузки части объектов вплоть до искомого. Метод можно оптимизировать за счет использования «ленивой загрузки» («lazy load») для каждого последующего элемента, пока идет процесс сравнения с уже загруженными экземплярами;
Remove(Object) – удаление элемента из коллекции. Также не требует загрузки других элементов коллекции;
int Count() – определение числа элементов коллекции. Может быть выполнен отдельным SQL-запросом вида SELECT Count(*) FROM… без непосредственной загрузки объектов;
GetEnumerator() – последовательный перебор элементов коллекции. Вместо последовательной загрузки объектов коллекции может быть выполнен одним SQL-запросом с выборкой всех объектов, входящих в коллекцию.
Использование специального метода GetEnumerator() может решить и описанную в начале статьи проблему с автоматической оптимизацией массового обновления объектов одного типа. В объектной модели массовое обновление объектов может выглядеть как:
foreach(invoice in InvoiceCollection)
{
Invoice.Recaulculate(10);
}
Обычная реализация метода Recaulculate(percent):
class Invoice
{
void Recalculate(int percent)
{
Total = Total*(100+percent)/100;
}
}
приведёт к множеству однотипных SQL-команд обновления.
Для их оптимизации следует создать специальный (custom) Enumerator, который будет использован для выполнения одной или нескольких сгруппированных команд обновления:
class InvoiceEnumerator
{
static Invoice[] InvoiceCollection;
static int[] PercentParameterCollection;
}
class Invoice
{
void Recalculate(int percent)
{
InvoiceEnumerator.InvoiceCollection.Add(this);
InvoiceEnumerator.PercentParameterCollection.Add(percent);
}
}
При завершении перебора в цикле foreach InvoiceEnumerator может объединить в одну или несколько SQL-команд обновления для всех объектов Invoice с соответственно одинаковыми значениям параметра percent из PercentParameterCollection.
Оптимизация последовательности запросов осуществляется за счет создания и использования дополнительных структур данных в памяти. Поэтому при оптимизации следует оценить расход оперативной памяти на эти структуры. Как видно из примеров выше потребление памяти будет расти пропорционально количеству типов объектов в объектной модели и не зависит от количества экземпляров объектов, что позволяет предположить эффективность использования для реальных баз данных, где количество экземпляров значительно превосходит число сущностей.
Рассмотренные методы оптимизации могут быть успешно использованы при разработке подсистем ORM для приложений, характеризующихся большим числом запросов пользователей. Примером таких приложений, получивших широкое распространение, являются сложные web-приложения с развитой бизнес-логикой, находящиеся в открытом (публичном) доступе. Одним из свойств таких приложений является большая разнородность запросов, что требует наличия возможности динамического и переключения методов оптимизации в процессе исполнения запросов.
Литература
1. Booch, G. Object-Oriented Analysis and Design with Applications. 2-nd ed. Addison-Wesley, Rational, Santa Clara, California. (1994). (Буч Г. Объектно-ориентированный анализ и проектирование с примерами приложений на C++, 2-е изд./Пер. с англ. – М.: «Издательство Бином», СПб.: «Невский диалект», 1999г. – 560 с., ил.)
2. Gruber, M. SQL Instant Reference. Sybex, Alameda, CA. (1993). (Грабер М. Справочное руководство по SQL. Пер. с англ. – М.: “Лори”, 1998. - 291 с.)
3. Date, C.J. An Introduction to Database Systems. Addison-Wesley, Reading, Massachusetts. (1995). (Дейт К. Дж. Введение в системы баз данных. - Киев: “Диалектика”, 1998. - 784 с.)
4. Stroustrup B., The C++ programming language. 3-d ed. Addison-Wesley, AT&T Labs Murray Hill, New Jersey. (1997) (Страуструп Б. Язык программирования С++, 3-е изд. Пер. с англ. – СПб.; М.: «Невский Диалект» – «Издательство БИНОМ», 1999 г. – 991 с., ил.)
5. Codd E.F. “A Relational Model for Large Shared Data Banks”. Communications of the ACM, 13, 6, June 1970, p.p. 377-387.
6. Maier D. The Theory of Relational Databases. Computer Science Press, Rockville, Maryland (1983). (Д. Мейер. Теория реляционных баз данных. М.: Мир, 1987. 608с.)
7. Archer, Tom. Inside C#. 2-nd ed. Microsoft Press A Division of Microsoft Corporation One Microsoft Way Redmond, Washington. (2002)
8. Malcolm Atkinson, Francois Bancilhon, David DeWitt, Klaus Dittrich, David Maier, and Stanley Zdonik: “The Object-Oriented Database System Manifesto”, Proc. 1st International Conference on Deductive and Object-Oriented Databases, Kyoto, Japan (1989). New York, N.Y.: Elsevier Science (1990). (М. Аткинсон и др. “Манифест систем объектно-ориентированных баз данных”, СУБД, No. 4, 1995, http:// www. osp. ru/ dbms/1995/04/23.htm )
9. M. Stonebraker, L. Rowe, B. Lindsay, J. Gray, M. Carey, M. Brodie, Ph. Bernstein, D. Beech. “Third-Generation Data Base System Manifesto” Proc. IFIP WG 2.6 Conf. on Object-Oriented Databases, July 1990, ACM SIGMOD Record 19, No. 3 (September 1990). (Стоунбрейкер М. и др. “Системы баз данных третьего поколения: Манифест”, СУБД, No. 2, 1996, http://www. osp. ru/ dbms/1995/02/23. htm )
10. Hugh Darwen and C. J. Date: The Third Manifesto. ACM SIGMOD Record 24, No. 1 (March 1995). (: Х. Дарвин, К. Дейт. “Третий манифест”, СУБД, No. 1, 1996, http:// www. osp. ru/ dbms/1996/01/23. htm )
11. ODBMS.ORG. Object Database Vendors. http://www.odbms.org/vendors.html
12. Martin Fowler, David Rice, Matthew Foemmel, Edward Hieatt, Robert Mee, Randy Stafford. Patterns of Enterprise Application Architecture. Addison Wesley. (2002)
13. Object Architects. O/R Mapping Products. http://www.objectarchitects.de/ObjectArchitects/orpatterns/Appendices/products.htm
14. Scott W. Ambler. Mapping Objects to Relational Databases: O/R Mapping In Detail. Ambysoft Inc. (2006) http://www.agiledata.org/essays/mappingObjects.html
15. Dan Tow. SQL Tuning. O'Reilly & Associates, Sebastopol , CA. (2003)
16. Thuan L. Thai, Hoang Lam. .NET Framework Essentials, 2nd Edition. O’Reilly (2002)
17. hibernate.org – Hibernate http://www.hibernate.org/
18. hibernate.org - A Short Primer On Fetching Strategies. http://www.hibernate.org/315.html
19. hibernate.org - Some explanations on lazy loading. http://www.hibernate.org/162.html
Публикации с ключевыми словами: информационные системы, базы данных, СУБД
Публикации со словами: информационные системы, базы данных, СУБД
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||